

オンラインゲームやアドホック通信の通信処理は、どのようなプログラムで動いているんでしょうか?
私は 15 年前くらいに、WinSock を使ってソケット通信のプログラムを組んだことがありますが、あれからもうずいぶんと長い年月が経ってしまいました。
IT の技術は 5 年もすれば化石になるので、思いついたついでに学び直すことにしました。
本稿では、私が学び直したことを、C++ 初心者だったころの自分が理解できるように説明する…というていで進めようと思います。
筆者はゲーム開発特化型なので、ゲームプログラミングの観点で読み解きます。
動作環境
Windows 11 Home
Visual Studio 2022
C++20
更新履歴
25/04/20 記事を公開
- サンプルコードについて。
- サンプルコード。
- Visual Studio 2022 のインストール。
- asio のインストール。
- Visual Studio ソリューションの作成。
- 動作確認。
- サンプルコードを読み解く。
- ソケット通信
- 改善点の検討。
- 参考になりそうな記事
本稿のサンプルコード(後述)は、AI に
win32 api を使わずに c++20 で udp でソケット通信するプログラムを教えて
と質問して、AI が提示してくれたコードです。
AI が提示するコードは古かったり間違っていたりするので、もっとモダンな方法や優れた方法があるかも知れません。
#include <iostream>
#include <asio.hpp>
int main() {
try {
asio::io_context io_context;
asio::ip::udp::socket socket(io_context, asio::ip::udp::endpoint(asio::ip::udp::v4(), 8080));
std::array<char, 1024> recv_buffer;
asio::ip::udp::endpoint remote_endpoint;
while (true) {
asio::error_code error;
size_t length = socket.receive_from(asio::buffer(recv_buffer), remote_endpoint, 0, error);
if (error) {
std::cerr << "Receive error: " << error.message() << std::endl;
continue;
}
std::cout << "Received from " << remote_endpoint << ": " << std::string(recv_buffer.data(), length) << std::endl;
std::string message = "Server received: " + std::string(recv_buffer.data(), length);
socket.send_to(asio::buffer(message), remote_endpoint);
}
}
catch (std::exception& e) {
std::cerr << "Exception: " << e.what() << std::endl;
}
return 0;
}
#include <iostream>
#include <asio.hpp>
int main() {
try {
asio::io_context io_context;
asio::ip::udp::socket socket(io_context, asio::ip::udp::endpoint(asio::ip::udp::v4(), 0));
asio::ip::udp::resolver resolver(io_context);
asio::ip::udp::endpoint remote_endpoint = *resolver.resolve(asio::ip::udp::v4(), "127.0.0.1", "8080").begin();
std::string message = "Hello from client!";
socket.send_to(asio::buffer(message), remote_endpoint);
std::array<char, 1024> recv_buffer;
asio::error_code error;
size_t length = socket.receive_from(asio::buffer(recv_buffer), remote_endpoint, 0, error);
if (error) {
std::cerr << "Receive error: " << error.message() << std::endl;
}
else {
std::cout << "Received: " << std::string(recv_buffer.data(), length) << std::endl;
}
}
catch (std::exception& e) {
std::cerr << "Exception: " << e.what() << std::endl;
}
return 0;
}
どちらも AI が提案したコードですが、まったく手直しすることなく動作しました。
ソケット通信のプログラムについてまったく知らない人からすれば、サンプルコードを見ても何がなんだか分からないと思いますので、これから詳しく読み解いていきます。
このサンプルコードをビルドするには、asio ライブラリが必要ですので、asio ライブラリのインストール方法についても順を追って説明します。
既にお持ちの方はスキップしてください。

Visual Studio は個人なら無料で使えます。
法人の場合はライセンスをよくご確認ください。
Visual Studio を使うのは、いろいろと楽だからです。
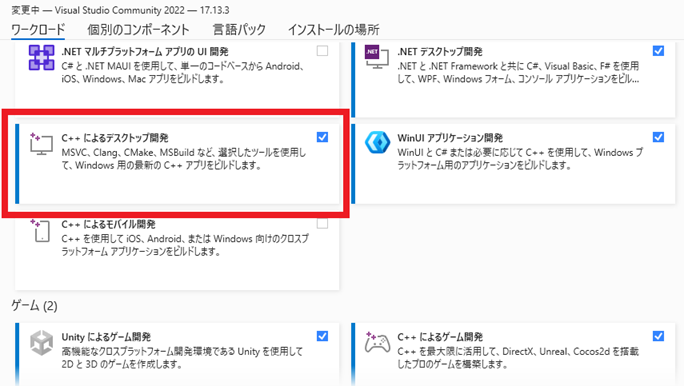
「C++ によるデスクトップ開発」にチェックを入れてインストールします。
他はお好みでどうぞ。
asio は boost に入ってますが、asio だけ独立させたライブラリがあります。
ただし、boost 版の asio を使う場合はサンプルコードの修正が必要になります。
本稿では、boost 版の asio は使いません。ちなみに boost 版は Boost.Asio と言うようです。
ざっと流れだけ説明すると、
1. zip をダウンロード。
2. 解凍。
3. 任意の場所にコピー。
以下、詳しい手順です。
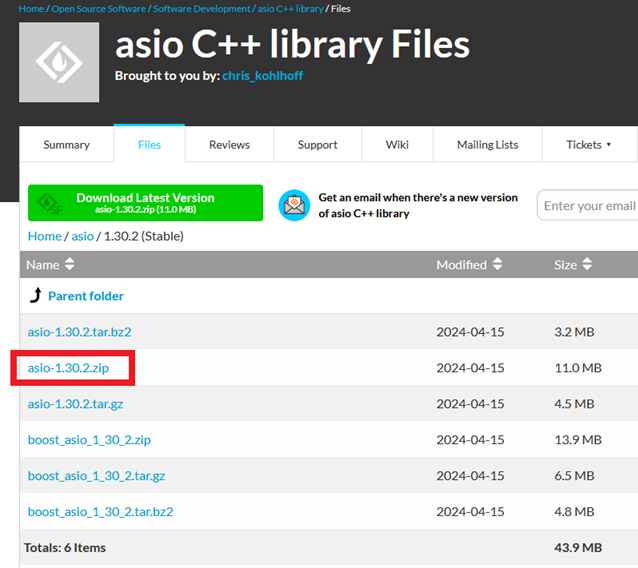
boost パッケージもダウンロードできますが、必要なのは asio だけなので、赤枠で囲った zip をダウンロードします。
Visual Studio のパッケージマネージャーで検索すると asio は見つかるんですが、何故かインストールに失敗するので、上記のサイトからダウンロードします。
asio は boost の中に含まれているので、パッケージマネージャーから boost をインストールしても使えます。
ただ、asio を使用している全ての箇所に名前空間 boost:: を付けないとならないので、純粋にコードを書く手間が増えてめんどくさいです。
Windows 11 なら解凍ソフトは必要ないですが、解凍スピードが遅すぎるので、私は「Bandizip」を使っています。

解凍したフォルダを好きな場所にコピーします。
C ドライブ直下が良いです(パスを入力するのが楽なので)。
サンプルコードのサーバー用とクライアント用は、それぞれ別のソリューションでビルドする必要があります。
手順は以下。
1. Visual Studio 2022 を起動。
2. 新しいプロジェクトの作成。
3. 空 (から) の C++ プロジェクトを選択。
4. main.cpp をプロジェクトに追加。
5. main.cpp にサンプルコードをコピペ。
6. asio にパスを通す。
7. ビルド。
以下、詳細です。
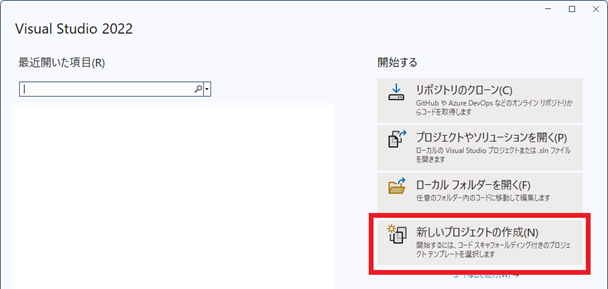
Visual Studio 2022 を起動して「新しいプロジェクトの作成」を選択。
![]()
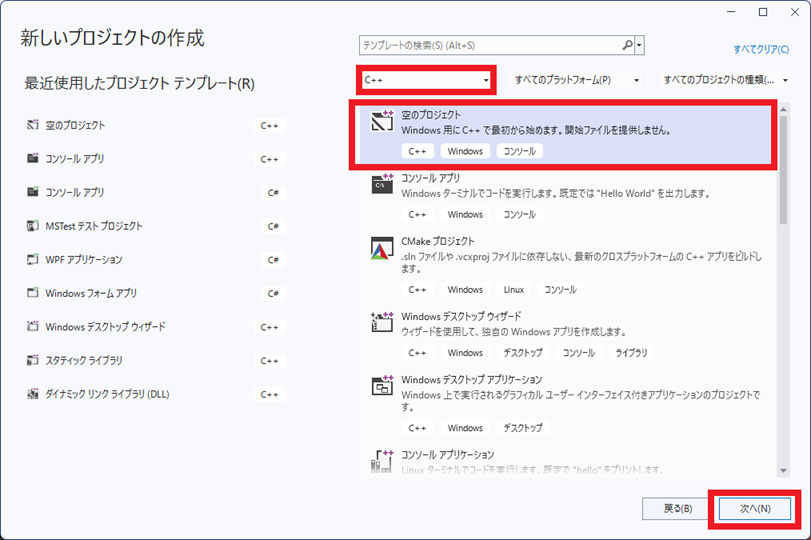 「C++」⇒「空のプロジェクト」⇒「次へ」の順に選択。
「C++」⇒「空のプロジェクト」⇒「次へ」の順に選択。
![]()
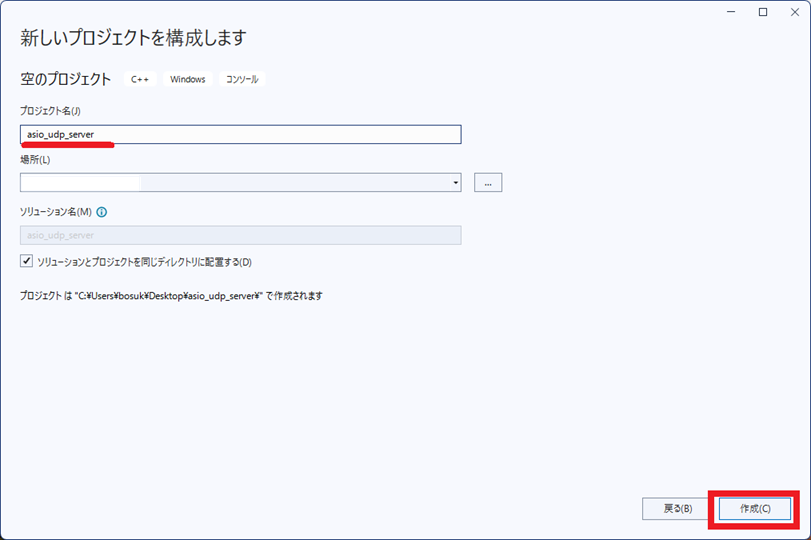 プロジェクト名(asio_udp_server)を入力⇒「作成」を選択。
プロジェクト名(asio_udp_server)を入力⇒「作成」を選択。
![]()
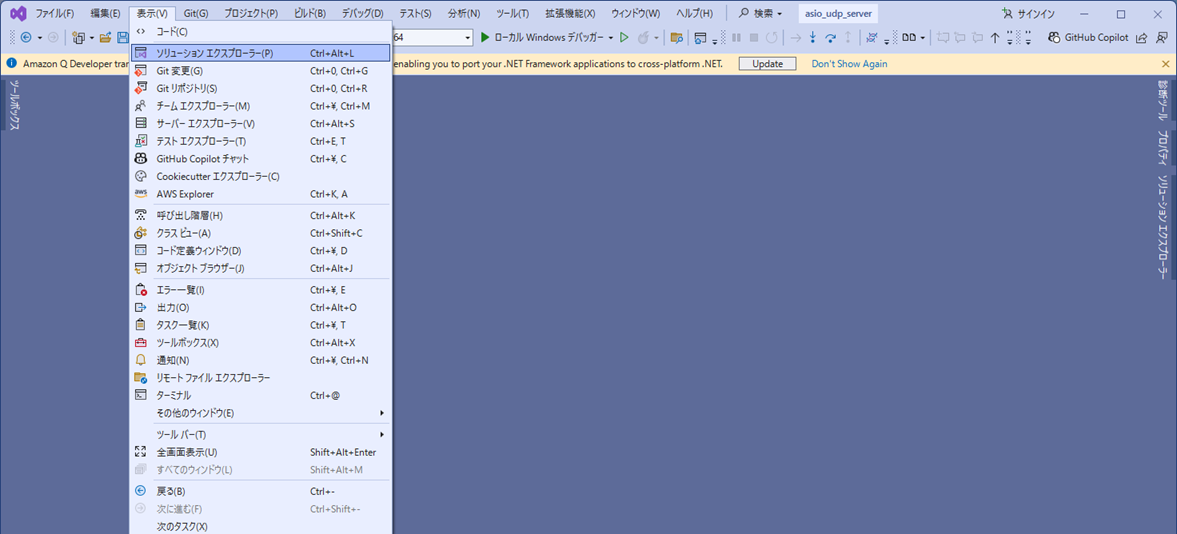 「ソリューションエクスプローラー」を開く。
「ソリューションエクスプローラー」を開く。
開き方は以下の 2 通り。
1. メニュー⇒表示⇒ソリューションエクスプローラー。
2. ウィンドウ右端にある「ソリューションエクスプローラー」タブをクリック。
![]()
「ソリューションエクスプローラー」⇒「ソースファイル」を右クリック⇒「追加」⇒「新しい項目」を選択。
![]()
ファイル名入力欄が表示されるので「main.cpp」を入力して「追加」を選択。
![]()
真っ白な main.cpp が表示されるので、本稿のサーバー用サンプルコードをコピペ。
![]()
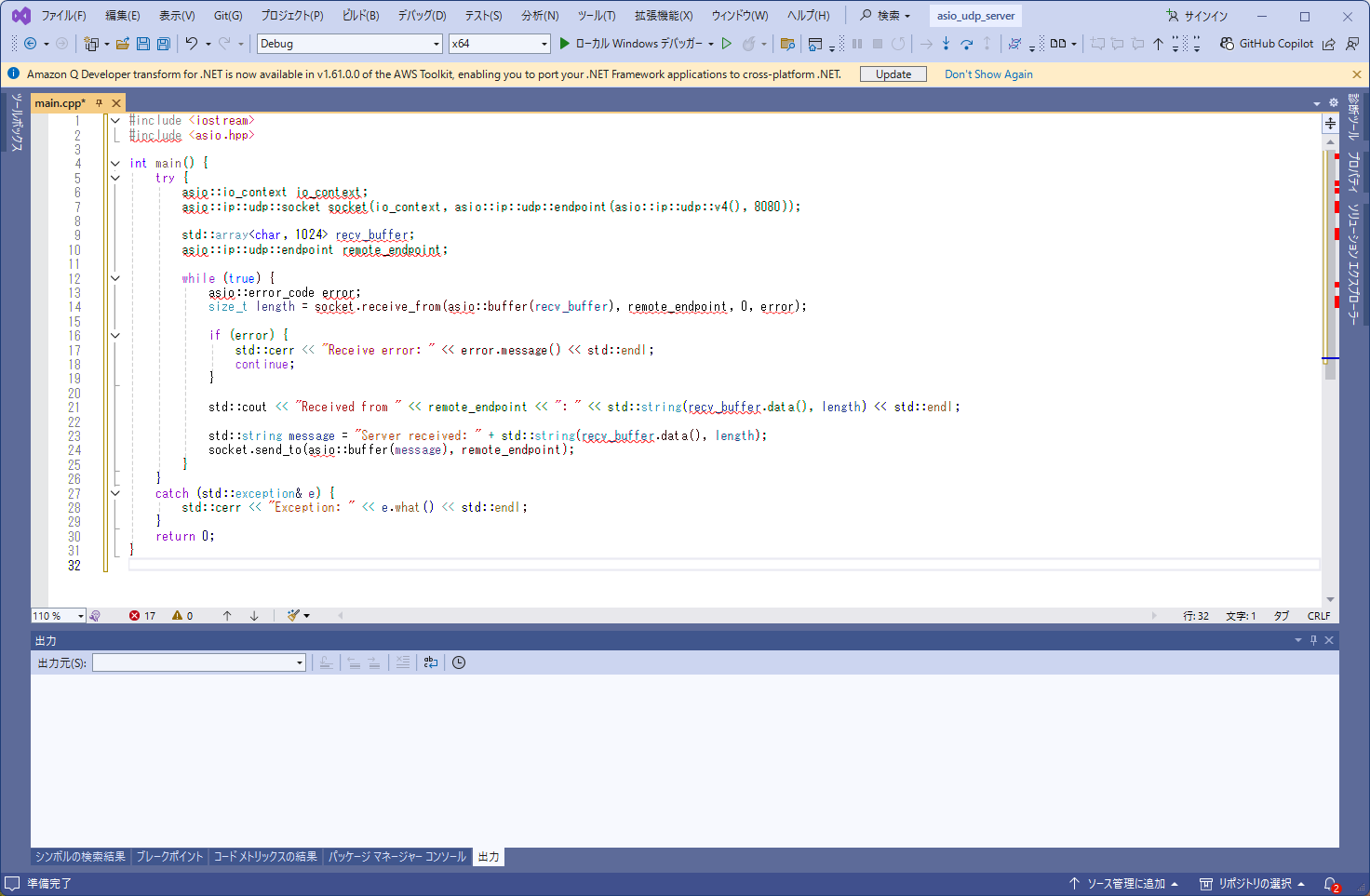
上図はコードをコピペしたところ。
asio にパスを通していないので、インテリセンスが赤い波線を引いて警告してくれてます。
とりあえず、Ctrl + S で上書き保存しておきます。
![]()
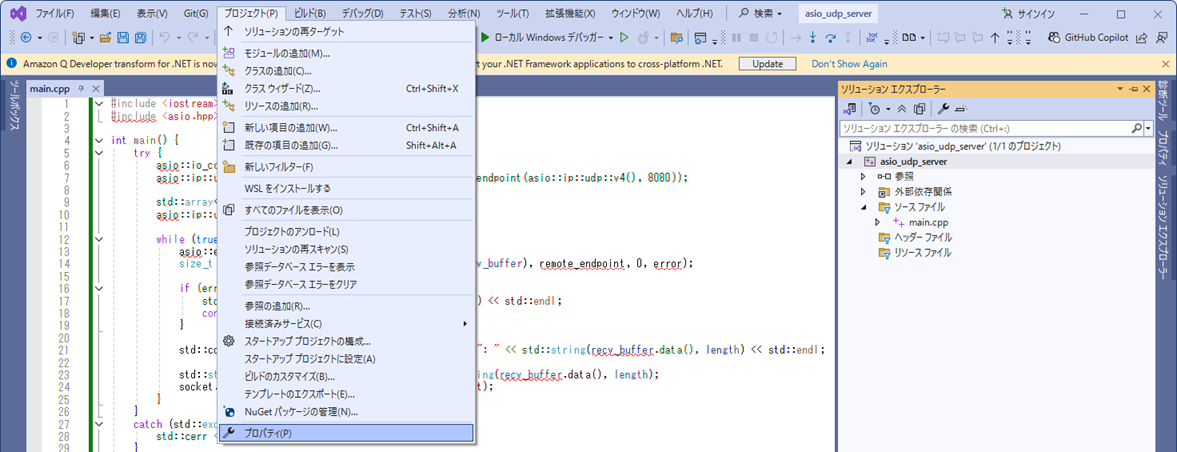
asio にパスを通すには、プロジェクトのプロパティーを変更する必要があります。
プロジェクトのプロパティーにアクセスする方法は以下の2通り。
1. メニュー⇒プロジェクト⇒プロパティ。
2. 「ソリューションエクスプローラー」⇒「asio_udp_server」(上から 2 番目)を右クリック⇒プロパティ。
![]()
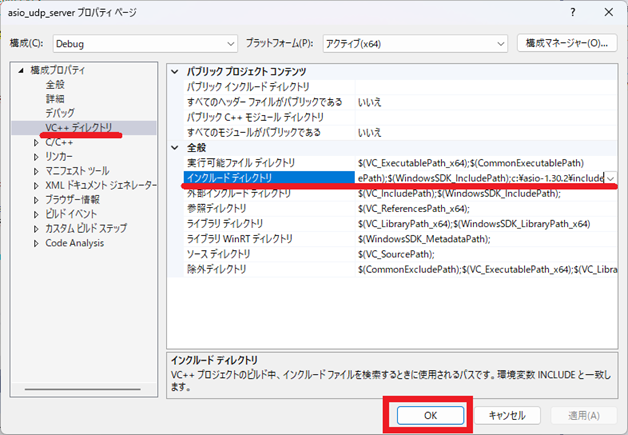
「VC++ ディレクトリ」⇒「インクルードディレクトリ」に asio をコピーしたフォルダの include フォルダへの完全パスを追加⇒「 OK 」を選択。
※C ドライブ直下に asio-1.30.2 をコピーした場合は、C:\asio-1.30.2\include
![]()
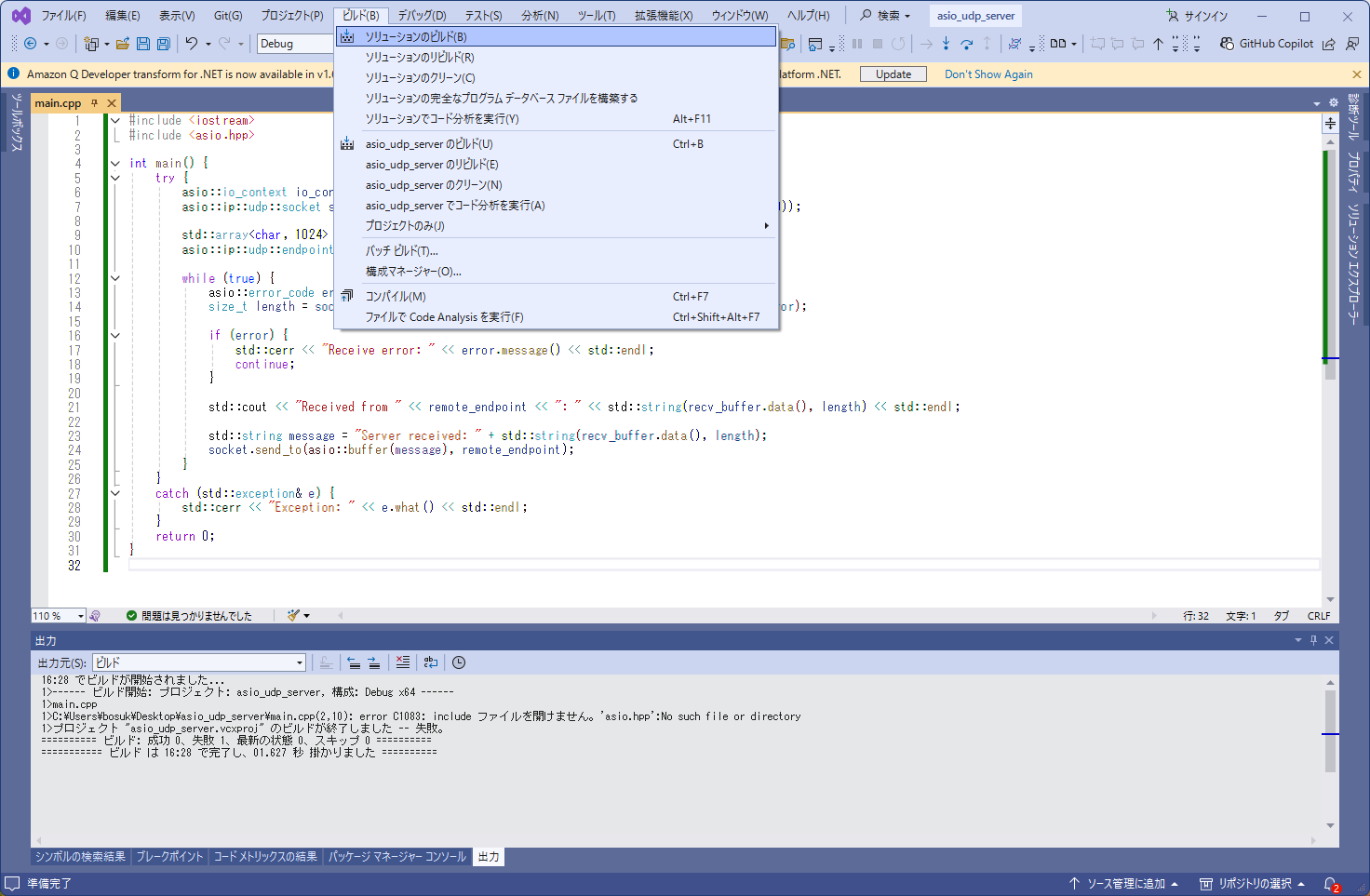
「ソリューションのビルド」を実行。方法は 2 通り。
1. メニュー⇒ビルド⇒ソリューションのビルド。
2. 「ソリューションエクスプローラー」⇒「ソリューション ‘asio_udp_server’」を右クリック⇒ソリューションのビルド。
![]()
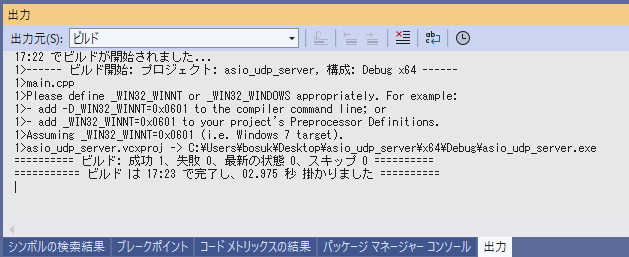
asio へのパスが通っていれば、ビルドが通ると思います。
サーバー用と手順は同じです。
サーバー用のソリューションは開いたままにしておきます。
再度、Visual Studio 2022 を起動するところから始めます。
プロジェクト名を考えるのが面倒でしたら asio_udp_client で作成。
main.cpp にはクライアント用サンプルコードをコピペ。
asio へのパス設定も必要です。
サーバーとクライアント型の通信プログラムは、基本的にサーバーを起動してからクライアントを起動するという順番で動作確認します。
1. サーバーでクライアントの接続を待ち受ける。
2. クライアントは待ち受け中であろうサーバーに接続する。
…という使い方を想定しているためです。
きちんとエラー処理が行われることを確認するために、わざとサーバーを起動しないでクライアントを起動することもあります。
サーバー側の Visual Studio でプログラムを実行。
実行方法は以下の 3 通りあるので、お好きな方法で。
1. メニュー⇒デバッグ⇒デバッグの開始。
2. F5 を押す。
3. ローカル Windows デバッガー を押す。
サーバーを起動しただけでは、特に何も表示されません。
何も表示されませんが、クライアントの接続を待ち受けている状態です。
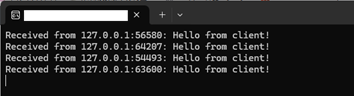
サーバーを起動してから、クライアント側のプログラムを実行。
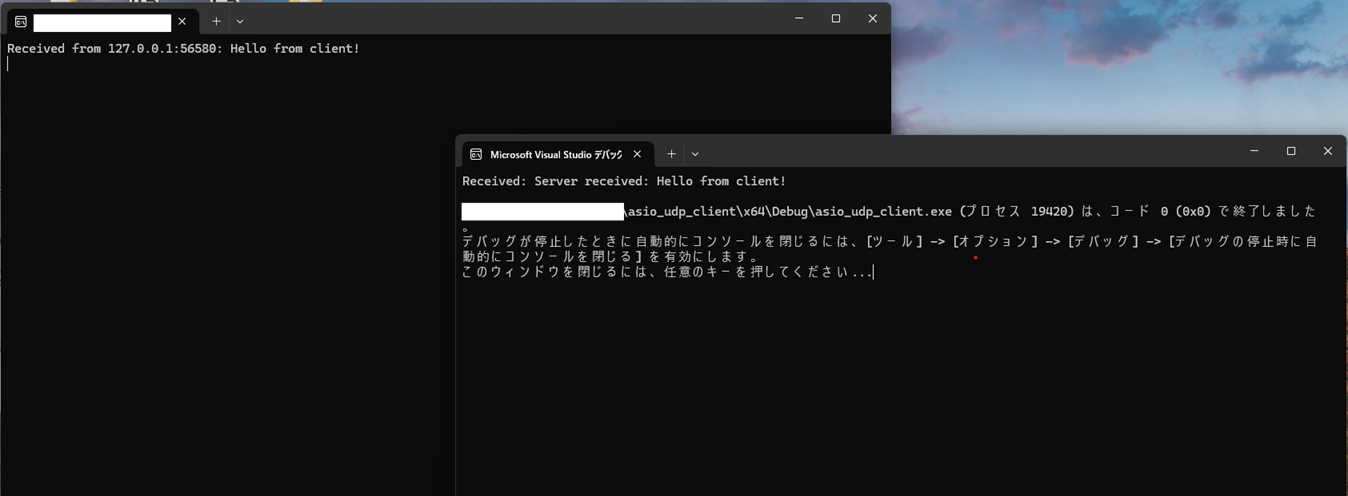
サーバーを起動したまま、クライアントを起動することで、サーバー側とクライアント側の双方にメッセージが表示されます。
待ち受け状態のサーバーにクライアントが UDP のソケット通信で接続し、サーバー側で接続を確認できた…ということになります。
サーバーを起動したまま、クライアントを何度も起動してみてください。
クライアントを起動する度に、サーバー側のメッセージが増えて行きます。
サーバー側とクライアント側のサンプルコードを丁寧に読み解いていきます。
C++ 初心者でも知っているであろう部分は割愛します。
これは説明要らないと思います。
#include <boost/asio.hpp> じゃないとビルドが成功しない場合は、boost 版の asio を参照しています。
本稿は boost 版は使わない方針ですが、boost 版を参照していても、ビルドが通ったのならそれで良いです。
#include “hoge”
#include <hoge>
インクルードパスを挟む方法は上記の 2 通りあります。
これ、何が違うのか分かりますか?
ざっくりとした使い分け方は、チームの慣習に従っておけば良いです。
例えば、アンリアルエンジンはほぼ “” (二重引用符) しか使わないですし、標準 C++ ライブラリ (iostream や algorithm などなど) には <> (やまかっこ) しか使わないです。
これには理由があります。
Visual Studio の場合、詳細は以下のようになります。
1. #include が書かれているヘッダファイルがある場所を検索。
#include "hoge/moge/bubera/orz.h" は、hoge/moge/bubera/ フォルダ内
↓
2. #include パスのコード内にある #include パスがある場所、更にその #include パスが…の順に検索。
#include "hoge/moge/bubera/orz.h" が hoge/moge/pugera.h をインクルードしているなら、hoge/moge/ 内、purage.h が abeshi/hidebu.h を…
↓
3. /I コンパイラオプションに指定したパス、または、プロジェクトのインクルードパス設定から検索。
プロジェクトのインクルードパス設定は、サーバー用のソリューションを作成 6. asio にパスを通す…で説明した設定方法のことです。
↓
4. INCLUDE 環境変数に指定しているパスを検索。
1. /I コンパイラオプションに指定したパス、または、プロジェクトのインクルードパス設定から検索。
↓
2. INCLUDE 環境変数に指定しているパスを検索。
公式ドキュメント

標準 C++ ライブラリや、サードパーソンライブラリはインストールする場所がほぼ固定なので、インクルードパスの検索時間を短縮するために <> (やまかっこ) を使うのが良いです。
大規模プロジェクトになるとコンパイルするコードも大量にあるので、こういうちょっとした時短がコンパイル時間の大きな短縮に繋がります。
※本当に大切なことです。
try catch は C++ 初心者でも知っていると思いますので、説明は割愛します。
ここで言いたいのは、asio は例外を投げるということです。
例外はゲームプログラミングとの相性が悪いです。
ゲームプログラミングでは、基本的にエラーが起きたときは例外を投げず、エラーコードを使うか、アサートを使ってその都度分かりやすい形で通知します。
例外を使わない理由は、パフォーマンスに悪影響が出るためです。
オンラインゲームでも、サーバー側の処理が重くなるとクライアントへのレスポンスが遅延して、キャラがワープしたり、ガクガク動くといった、いわゆるラグの原因になります。
特にアクションゲームでは、クライアント側とのタイミングを合わせるために、サーバー側も秒間 60 フレームのタイミングを取る必要が出てきます。
try catch は、サンプルコードのように main 関数の中だけにとどめるようにします。
関数呼び出しの深い階層で例外が出た場合、try catch があるところまでスタックを遡ってくれるので、main 関数の中にひとつあれば良いです。
パフォーマンスの問題で main 関数の中で使えない場合、例外を投げて来る処理に対してのみ使います。
間違っても for や while の中で使ってはいけません。
難しい場合は、例外を投げて来る部分だけをマルチスレッド化して、そのスレッドの中で使います。
asio::io_context io_context;
asio で何らかの一連の処理を実行するときに必要になるクラスです。
そのクラスのインスタンスを生成しています。
これを次の行のソケットに与えることで、ソケットの処理を進めたり、止めたりしているのではないかと思われます。
この io_context は、次の行の socket を削除するまで保持しておく必要があります。
// 実行時にエラーになる
std::unique_ptr<asio::ip::udp::socket> socket;
{
asio::io_context io_context;
socket.reset(new asio::ip::udp::socket(io_context, asio::ip::udp::endpoint(asio::ip::udp::v4(), 8080)));
// このブロックを抜けたときに io_context が削除され、エラーになる
}
// エラーにならない
std::unique_ptr<asio::ip::udp::socket> socket;
std::unique_ptr<asio::io_context> io_context{new asio::io_context()};
{
socket.reset(new asio::ip::udp::socket(*io_context, asio::ip::udp::endpoint(asio::ip::udp::v4(), 8080)));
// io_context を削除してはいけない
}
従って、io_context の寿命は socket より長くする必要があるため、socket が不要になるまで保持する必要があります。
寿命が長いインスタンスに対しては、スタックではなくヒープを使うべきです。
※AI が提示したサンプルコードは運用することを想定していないため、このようなコードになっていると思われます。
// asio::ip::udp::socket socket(io_context, asio::ip::udp::endpoint(asio::ip::udp::v4(), 8080)) //
次はこの 1 行について読み解きますが 1 行に情報を詰め込みすぎです。
ひとつずつ分解して見て行きます。
UDP でソケット通信を行うクラスのインスタンスを生成しています。
これもスタックを使っています。
asio ライブラリで
ip => インターネットプロトコルの
udp => UDP を使う
socket => ソケット通信。
必要な情報が凝縮されているので、とても分かりやすいです。
いくつもの名前が :: (ダブルコロン) で繋がっていますが、ぱっと見で、それぞれが名前空間なのか、クラスなのか、関数なのか見分けがつきません。
以下のようになっています。
| asio | 名前空間 |
| ip | 名前空間 |
| udp | クラス |
| socket | basic_datagram_socket クラスの別名 (エイリアス) |
余計な部分を省いたコードにすると以下のようになります。
namespace asio {
namespace ip {
class udp {
public:
typedef basic_datagram_socket<udp> socket;
};
} // namespace ip
} // namespace asio
名前空間 (namespace) はカテゴライズするためのもので、ネストして何重にも付けることができます。
適切に名前空間を使うことで、その中で宣言する構造体やクラスなどの名前を簡潔に書くことができます。
C++17 以降であれば、namespace asio::ip { } とまとめて書くことができます。
分かりにくいのは、typedef basic_datagram_socket<udp> socket; この部分だと思います。
コードを簡潔に記述できるよう、asio::ip::udp::socket で宣言できるようにしていますが、実際は asio::basic_datagram_socket<udp> で宣言していることになります。
こういった別のものに置き換えた名前 (別名) をエイリアスと呼びます。
asio::ip::udp::socket asio::basic_datagram_socket<udp>
どっちで書いても意味は同じです。
ただ、この typedef があるということは、暗黙的に asio::ip::udp::socket の使用を推奨しているということだと思います。
また、この typedef の使い方は using を使っても同じことができます。
typedef basic_datagram_socket<udp> socket; using socket = basic_datagram_socket<udp>
どちらも意味は同じです。
私は using を使ったほうが分かりやすいので、using を使っています。
どっちで書くかは、多分、好みじゃないでしょうか。
あと、C++11 よりも前のとてつもなく古いコンパイラだと、using でのエイリアスは使えません。
要するに、socket クラスなんてものはないので、コードを確認したいときは、実際に存在する basic_datagram_socket クラスで検索する必要があります。
ソケットを生成するのに必要な引数のひとつです。
関数呼び出しに見えるんですが、クラスのインスタンスを生成しています。
この asio::ip::udp::endpoint もエイリアス (別名) なので、実際には存在しないクラスです。
実際のクラスは asio::basic_endpoint<udp> です。
スタックを使う場合、クラスのインスタンスを宣言する書式は、通常以下のようになります。
クラス名 インスタンス名;
クラス名 インスタンス名(コンストラクタの引数リスト);
インスタンス名を宣言してから引数を指定するのが一般的ですが、ここではインスタンス名が省略されています。
これはコンストラクタを一時オブジェクトとして使う方法で、この使い方については以下の記事がとても参考になります。
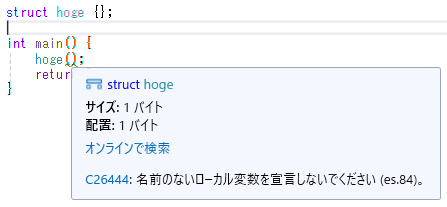
警告なのでビルドは成功して実行できるんですが、正常に動作しません。
#include <iostream>
using namespace std;
struct hoge {};
struct moge {
moge(const hoge& h) {}
};
int main() {
moge m(hoge());
return 0;
}
このコードを Visual Studio でコンパイルすると、以下の警告が出ます。
warning C4930: 'moge m(hoge (__cdecl *)(void))': プロトタイプされている関数が呼び出されませんでした (変数の定義が意図されていますか?)
関数呼び出しなのか、インスタンスの宣言 (コンストラクタの呼び出し) なのか分からないようです。
struct hoge {
hoge() {} // コンストラクタ
const hoge& operator()() { return *this; } // ファンクタ
};
もし、コンパイラがこれを想定しているなら、確かにどっちか分からないですね。
ファンクタはインスタンスを宣言して、そのインスタンスから呼び出します。
hoge h; h(); // ファンクタ operator() の呼び出し
であれば、moge m(hoge()()); こうなるはずなので、ファンクタではなさそうです。
更にこうしてみます。
struct hoge {
hoge() { cout << "hoge" << endl; }
const hoge& operator()() {
cout << "hoge::operator()" << endl;
return *this;
}
};
struct moge {
moge(const struct hoge& h) {}
};
// struct hoge のインスタンスを生成して返す関数
struct hoge& hoge() {
cout << "function hoge()" << endl;
static struct hoge h;
return h;
}
int main() {
moge m(hoge());
return 0;
}
これを Visual Studio でコンパイルして実行すると、function hoge() が呼ばれます。
MSVC は hoge() と書いた場合、優先的に関数呼び出しと判断するようです。
hoge() 関数があると、どうやっても struct hoge の一時オブジェクトを使うことができなくなってしまいます (と言ってもこの場合は必要ないですが) 。
hoge() 関数は削除して、一時オブジェクトであることを明確にすることで正常に動作するようになります。
moge m(hoge{}); // () を {} に変更
{} を使うことで、インスタンスの初期化 (コンストラクタの呼び出し) であることを明示することができます。
一時オブジェクトに対してファンクタを呼び出したいなら、以下のようにします。
moge m(hoge{}()); // {}
これは、コンストラクタが引数を持たない場合の話で、hoge のコンストラクタがひとつでも引数を持っていれば、こんなことに注意する必要はなくなります。
struct hoge {
hoge(int a) { cout << "a=" << a << endl; }
};
struct moge {
moge(const hoge& h) {}
};
int main() {
moge m(hoge(123)); // 引数がひとつでもあれば () を使える
return 0;
}
asio::ip::udp::endpoint(引数)
endpoint のコンストラクタは引数を持っているため、コンパイラが警告を出すこともなく、正常に動作するということです。
endpoint のインスタンスが一時オブジェクトとして生成されますが、socket のコンストラクタが受け取るのは参照です。
一時オブジェクトとして生成されたインスタンスの寿命は、コンストラクタに入ってすぐに尽きたりはせず、参照のおかげで延命されます。
「じゃあ、どこまで延命されるのか?」というのが問題で、結論から言うと socket のコンストラクタを抜けるまでです。
それ以上は保持されません。
もっと寿命を延ばしたいのであれば、一時オブジェクトを使わない、あるいは、参照ではなくコピーを使う必要があります。
もし、socket がメンバ変数に endpoint の参照を持っていて、一時オブジェクトをそのメンバ変数に渡したとしても、メンバ変数の参照先は socket のコンストラクタを抜けた時点で無効になってしまいます。
従って、以下のような使い方は危険です。
struct hoge {
~hoge() { cout << "~hoge" << endl; }
};
struct moge {
moge(const hoge& h) : h_(h) {} // 参照型のメンバ変数に渡す
~moge() { cout << "~moge" << endl; }
const hoge& h_;
};
int main() {
{
moge m(hoge{}); // 一時オブジェクトをコンストラクタに渡す
cout << "block end" << endl;
}
return 0;
}
実行結果
~hoge
block end
~moge
block end の前に ~hoge (のデストラクタ) が呼ばれているので、moge のコンストラクタを抜けた時点で、hoge の寿命が終わっています。
h_ は moge が死ぬまで存在しますが、参照先は moge のコンストラクタを抜けた時点で死んでいます。
一時オブジェクトを使う場合は、hoge の寿命が moge のコンストラクタで終わることを想定した上で使用する必要があります。
endpoint は socket のコンストラクタで寿命が尽きることを想定した使い方をしているため、この書き方で問題ないということになります。
これは非常にややこしい仕組みなので、C++ の熟練者でなくても分かるように以下のように書くべきです。
(熟練者でも見落としたり、一時オブジェクトの仕組みを忘れていることもある。)
std::unique_ptr<asio::ip::udp::socket> socket;
{
const asio::ip::udp::endpoint endpoint{引数};
asio::ip::udp::socket* new_socket{new asio::ip::udp::socket(io_context, endpoint)};
socket.reset(new_socket);
// endpoint は socket のコンストラクタ内でのみ使われる。
// それ以上の寿命が必要なメンバは、コンストラクタ内で複製されるので
// endpoint の寿命がここで尽きても問題ない。
}
assert(socket.get());
if (socket.get() == nullptr) { /* エラー処理へ */ }
私が書くなら、最低でもこうします。
一時オブジェクトのような、見落としやすく、ややこしい使い方はしません。
endpoint の寿命が尽きたときに、endpoint が持っていた値がどうなるのかをコメントで明確にします。
もし、コメント通りの挙動になっておらず、それによって問題が発生した場合、このコードを書いた後に socket か endpoint の処理が変わったんだろう…という予想ができます。
(ある時点までは、ここで問題が発生していなかった…という前提ですが。)
であれば、socket のコンストラクタを修正するか、endpoint のメンバ変数を返す処理を修正すれば良いです。
あるいは、endpoint に渡している「引数」が間違っているか…ですね。
宣言するときに const を付けているので endpoint は参照用だと分かりますし、スタックを使ってインスタンスを生成していることが分かります。
引数が定数なら、おそらく、コンパイラが最適化してくれます。
仮にこのあたりのコードでバグが起きて、原因調査のためにデバッガでステップ実行するときも、endpoint と socket の宣言は行が分かれている方が楽です。
endpoint にステップインしたくないなら、そのままスキップできますし、socket の行でステップインするときも楽です。
asio::ip::udp::socket socket(io_context, asio::ip::udp::endpoint(引数));
サンプルコードのように 1 行に詰め込んでしまうと、socket にステップインしたくても、先に endpoint にステップインすることになるので、デバッガでステップ実行するときの手間が増えます。
また、io_context は長期間使われる可能性があるので、スタックではなくヒープを使います。
endpoint はサイズが小さいので、スタックに十分な空きがあればスタックでも問題ないです。
※ここに来るまでに巨大な配列をスタックで確保してたり、そういう巨大なデータをスタックで持っているクラスや構造体のインスタンスをいくつも保持していたり、何千何万もの関数呼び出しや for や while をネストしているなら、気を付けたほうが良いです。
「そもそもエンドポイントってなに?」の説明をもとにして考えると、asio::ip::udp::endpoint はデータの届け先を表現しているクラスと考えられます。
このエンドポイント用クラスは、データの届け先を識別するのに必要な最低限の情報として、IP アドレスとポート番号を持っている…ということになります。
asio::ip::udp::endpoint = asio::basic_endpoint<udp> のコンストラクタに与える引数ですが、これは udp クラスを生成して返しています。
ネットワークに詳しくない人からすると、「v4 ってなに?」と思うかも知れません。
これは IP アドレスのバージョンで、v4 はバージョン4ということです。
IP アドレスというのは、ふたつのプログラムでネットワーク機能を使って通信を行うときの宛先です。
今は手紙や荷物を郵送する機会はあまりないかも知れませんが、荷物を届けるには、送り先の住所(アドレス)が必要になります。
現実の世界では、東京都千代田区霞が関3丁目2−2(特に理由はないですが、文部科学省の住所です)みたいになるわけですが、ソケット通信の場合は 127.0.0.1 のような書き方になります。
0 から 255 までの数字を .(ドット)で区切って4つ組み合わせたものが IPV4 のアドレスです。
この数値の範囲は unsigned char 型で扱うことができます。
数値の変換は慣れないと難しいので、コードで書いてみます。
#include <iostream>
int main() {
std::uint8_t a = 127;
std::uint8_t b = 0;
std::uint8_t c = 0;
std::uint8_t d = 1;
std::cout << a << "." << b << "." << c << "." << d;
return 0;
}
IPV4 は、ドットを除いて数値を連結すれば 4 バイト(32ビット) で表現できます。
この変換を行う場合は 16 進数で表現して考えます(分かりやすいので)。
前述の 127.0.0.1 は以下のようになります。
16 進数で書くと 7F 00 00 01 になります。
ドットの位置に半角スペースを入れています。
16 進数の 7F は 10 進数で 127 です。
16 進数で表現した数値 (7F000001) を 10 進数に変換すると、2,130,706,433 になります。
これもコードで書いてみます。
std::uint32_t a = 127; std::uint32_t b = 0; std::uint32_t c = 0; std::uint32_t d = 1; std::uint32_t ipv4 = (a << 24) + (b << 16) + (c << 8) + d; std::cout << ipv4;
なんでこんなややこしい変換をするのかと言うと、通信量を減らすためです。
文字列の “127.0.0.1” をバイト数にすると、そのまま文字数を数えればいいので、9 バイトになります。
場合によっては、”255.255.255.255″ というように、15 バイトになる場合もあります。
最小は “0.0.0.0” なので、7 バイトです。
文字で表現すると 7 ~ 15 バイト必要です。
数値なら 4 バイトで済みます。
IP アドレスを相手に送る場合、数値を使ったほうが送信するデータサイズが節約できます。
本稿のサンプルコードでは、この変換は使いませんが、通信プログラムを扱っていると、このような変換が必要になるので、覚えていても無駄にはならないと思います。

127.0.0.1 は localhost と呼ばれ、回線を使わずに同じ PC の中で起動している異なるアプリ間で通信を行う場合に指定するアドレスです。
ネットワーク経由の通信については、本稿では扱いませんので、これ以上の説明は割愛します。
ネットワークが絡むと設定も準備も、すごい・なまら・すこだま・いら・でら・ばり・ごっつい・たいぎゃ・でぇじ、めんどくさい。
これはポート番号と呼ばれるもので、通信プログラムで宛先を指定するときに、IP アドレスとセットで必要になります。
ポートはそのまんま「港」とか、飛行場のポート (発着場) のことですが、この場合、データを受け取る処理なので、データを受け取る受付の窓口と考えたほうが良いと思います。
データを送る場合は、送り先の受付窓口になります。
例えば、大きなビルをひとつ持ってるような大企業のオフィスに荷物を届けることを想像すれば分かりやすいかも知れません。
IP アドレス (住所) でオフィスの場所は分かっても、じゃあ、このオフィスのどこの部署に届ければいいのか?が分かりません。
アドレスは同じでも、受付が無数にあるので、どの受付に持っていけばいいのか?を指定する必要があります。
現実だと、4F △部 〇課 みたいになると思いますが、それを番号で区別している…というようなイメージがポート番号で良いと思います。
ポート番号は通常 2 バイト (unsigned short) なので、0 ~ 65535 のどれかになります。
使用目的によって、よく使われるポート番号があったりしますが、おそらく、数値の範囲内なら何でも良いのではないかと思います。
asio::ip::udp::socket socket(io_context, asio::ip::udp::endpoint(asio::ip::udp::v4(), 8080))
ここまで説明した知見にもとづいて、この 1 行をより良い表現で記述するなら、どのように書けば良いでしょうか?
参考程度にどうぞ。
bool CreateUDPv4Socket(
std::unique_ptr<asio::ip::udp::socket>& socket, // [out]
const std::unique_ptr<asio::context> & io_context, // [in]
const std::uint16_t port_number // [in]
) {
if (io_context.get() == nullptr) { return false; }
socket.reset();
// IPV4 の UDP オブジェクト宣言
const asio::ip::udp udp {asio::ip::udp::v4()};
// udp とポート番号を使ってエンドポイントを生成
const asio::ip::udp::endpoint endpoint(udp, port_number);
// io_context とエンドポイントを使って UDP ソケットを生成
socket = std::make_unique<asio::ip::udp::socket>(*io_context, endpoint);
// udp と endpoint は socket のコンストラクタ内でのみ使われる。
// それ以上の寿命が必要なメンバは、コンストラクタ内で複製されるので
// endpoint の寿命がここで尽きても問題ない。
assert(socket.get());
return socket.get() != nullptr;
}
ソケットを生成する処理自体を関数化します。
生成したソケットは引数で受け取れるようにして、生成に失敗した場合に assert を実行した上で false を返します。
assert は開発環境でしか機能しないので、リリース版では false が返るだけです。
コード量が増えていますが、コードの行数が少なくてもデバッグしにくい、何をやっているのか分からない、変数の寿命を調べるのに時間がかかる…という状態だと、保守コストが上がります。
このコードならソケット生成に必要な処理や変数が全てひとつの関数に集約されるので、ソケット生成に何らかの問題が出たときは、この関数を調べるだけで済みます。
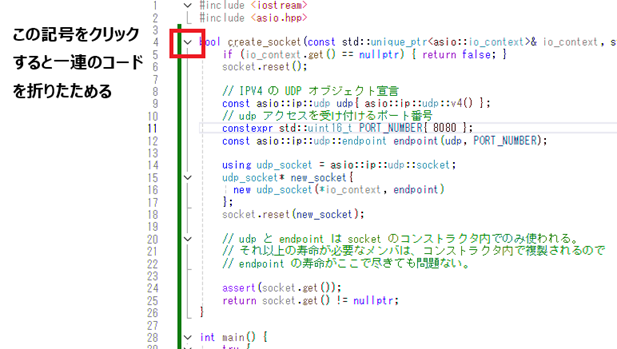
このように関連処理をブロック化すると、Visual Studio ならブロック単位でコードを折りたたむことができるので、見る必要がない部分を折りたたんでおけば、必要な部分のコードだけ確認できます。

クライアントから送られてくるデータを受け取るためのバッファを宣言しています。
char 型のデータを 1024 個確保しているので、1 キロバイト確保しています。
std::array はヒープを使わないので、スタックサイズが 1 キロバイトしかない環境だと、ここでスタックオーバーフローを起こします。
ヒープを使うなら以下のようにします。
// std::unique_ptr<std::array<char, 1024>> recv_buffer = std::make_unique<std::array<char, 1024>>(); //
vector を使っても良いのですが、受け取り用のバッファは std::array にする必要があるので、std::array をヒープに生成します。
std::array<char, 1024> は長いし、覚えにくいし、2 回書くのが面倒なので、using で短い名前のエイリアスを定義して、それを使うのが良いです。
using Buffer1k = std::array<char, 1024>; std::unique_ptr<Buffer1k> recv_buffer = std::make_unique<Buffer1k>(); //
asio::ip::udp::endpoint remote_endpoint;
asio::error_code error;
size_t length = socket.receive_from(asio::buffer(recv_buffer), remote_endpoint, 0, error);
if (error) {
std::cerr << "Receive error: " << error.message() << std::endl;
continue;
}
std::cout << "Received from " << remote_endpoint << ": " << std::string(recv_buffer.data(), length) << std::endl;
上記のコードは、クライアントからの接続の待ち受けと、待ち受けのエラー処理、受信したデータの表示までをサーバー側のサンプルコードから抜き出したものです。
上から順番に見て行きます。
スタックで生成したインスタンス remote_endpoint は receive_from から値を受け取るための変数です (クラスのインスタンスで、かつ、変数です) 。
この変数には、接続してきたクライアントの情報 (クライアント側の IP アドレス、クライアント側のポート番号) が入ります。
接続してきたクライアントに対して、サーバーからデータを送りたい場合の送り先として使います。
error (こちらもスタックで生成したインスタンス) は receive_from から値を受け取るための変数です。
名前の通り、何らかのエラーが起きた場合、エラーに関する情報が入ります。
宣言しているのは asio::error_code ですが、これはエイリアス (別名) で、実際の型は std::error_code です。
使い方はサンプルコードの通りです。
そのため、実際に使われている型 (クラスや構造体など) のコードを調べたいときに、その型が定義されているソースファイルを突き止めるのに時間がかかったり、コードを見ただけではたどり着くのが非常に難しい場合があります。
何故、わざわざ別名を使ってコードを複雑にしているのでしょうか?
そうした意図や理由はコードを書いた本人にしか分からないので一般論になりますが、以下のふたつの理由があると思われます。
(だから、コメントには意図を書く必要があるのです。)
1. コードを簡潔に書けるようにするため。
2. クラスの結合を弱めるため。
エイリアスを使う目的は、ほぼ 1. です。
C++ はとにかく型の扱いが厳格で、注意して扱わないとおかしな挙動をしたり、特定の環境で動かなくなったりします。
そういった意図しない振る舞いをしないよう、型を省略したりせず (auto の型推論もあてにならない)、あらゆる箇所を明示的に記述する必要が出てきます。
安全性を向上させるため、きっちり書いていると、どうしても文字数が多くなってしまいます。
テンプレート関数を使ったり、ラムダ式を書いたりすると 1 行が長くなってしまい、いちいち横スクロールしないと最後まで読めない…といった読みにくいコードになってしまいます (一般的に 1 行の長さは 80 文字が目安)。
可読性が低いコードは保守コストが高くなるので、読みやすくなるように改行を入れたりするのですが、それ以外にも、エイリアスを使って、分かりやすく、かつ、短い 文字数 の名前に置き換えることもできます。
例
{
// 一行が長すぎる
const TottemoNagaiNamaenoStruct& tottemoNagaiName = nanikanoInstance.GetMutableStruct<TottemoNagaiNamaenoStruct>(tottemoNagaiNamaenoOption);
// このブロック内で tottemoNagaiNamae を使う
}
どう見ても読みにくいです。
修正案
{
// このブロック内だけで使えるエイリアス
using Struct = TottemoNagaiNamaenoStruct;
// 短い名前の参照に置き換える
const NanikanoClass& instance = nanikanoInstance;
const int& option = tottemoNagaiNamaenoOption;
const Struct& name = instance.GetMutableStruct<Struct>(option);
// このブロック内で name を使う
}
長い名前に対して、短い名前のエイリアスの定義と参照型の短い名前の変数に置き換えています。
この曖昧な名前のエイリアスも変数も {} 内のごく狭いスコープでしか使えません。
曖昧な名前のものは、このブロック内を読んでいる間だけ覚えておけば良く、短い名前なので短期記憶に残しやすいです。
仮に、このブロックの行数が 10 を超える場合は、この修正案では不十分です。
そのようなケースでは、このブロックを、このソースファイル内だけで使えるローカルな関数にして、それを呼び出す形にします。
namespace { namespace Local {
void MakePuddingWithTottemoNagaiNamenoStruct(
const NanikanoClass& instance,
const int& option
) {
// このブロック内だけで使えるエイリアス
using Struct = TottemoNagaiNamaenoStruct;
const Struct& name = instance.GetMutableStruct<Struct>(option);
// このブロック内で name を使ってプリンを作る
}
}}
void SomeFunction() {
// とっても長い名前の構造体を使ってプリンを作る
Local::MakePuddingWithTottemoNagaiNamenoStruct(
nanikanoInstance,
tottemoNagaiNamaenoOption
);
}
このコードはローカルに閉じ込めておくためのものなので、ヘッダファイルに書いてはいけません。
ヘッダファイルに書いてしまうと、インクルードしたファイルで参照できるようになるため、ローカルではなくなります。
インクルードしても参照できないなら書く意味はないと思うのですが、C++ の言語仕様的にクラスや構造体のプライベートメンバをヘッダファイルに書く必要があります。
pimpl イディオムと呼ばれる抜け穴的なテクニックはありますが、コードを書く手間が増えるので私は好きではありません。
コードなんて書かなくて済むならそれが一番良いです。
コードを書かなければ、ロジックの矛盾、可読性、安全性、拡張性…などなど、いろいろと面倒なことを気にしなくて済みます。
コードを書くなんて単純作業は AI にまかせて、もっとクリエイティブな活動に集中できる時代がもうすぐ来ると思いますが、今はまだ泥臭くて七面倒なことをやる必要があります。
「2. クラスの結合を弱めるため。」については、オブジェクト志向プログラミングの知識がないと良く分からないと思いますので、コードで示します。
class x64 { public: void test() {} };
class ps5 { public: void test() {} };
class gege {
x64 _;
public:
void test() { _.test(); }
};
gege g;
g.test(); // x64::test() を呼び出している
ウィンドウズ専用アプリとして開発した当初、gege::test() は x64 ::test() を関数内で呼び出していました。
そのあと、PS5 へ移植することになり、PS5 では ps5::test() を呼び出す必要が出ました。
PS5 では x64::test() は使いません。
このようなケース (プラットフォーム移植) は、ある程度の規模のゲーム開発では普通にあります。
上記のクラス構成では、どのように対応するのが良いでしょうか?
このシチュエーションでは、x64 と ps5 しか出てきませんが、予算次第で xsx (xbox) や (nintendo) switch2 など、マルチプラットフォーム化するのが予想できますね。
一番簡単で、何の工夫もない方法は以下のようになると思います。
class gege {
#if PLATFORM_X64
x64 _;
#endif
#if PLATFORM_PS5
ps5 _;
#endif
public:
void test() { _.test(); }
};
これをやると、gege クラスは x64 クラスと、ps5 クラスの両方と依存関係ができてしまいます。
将来的に、対応プラットフォームの数だけ依存するクラスが増えます。
開発が進むに従って、x64 クラスを x64steam と x64epic に分けて実装する必要が出ました。
この変更が必要なのは gege クラスだけで、それ以外のクラスは引き続き x64 クラスを使うため、gege クラス側で切り替える必要が出ました。
class gege {
#if PLATFORM_X64 && PLATFORM_STEAM
x64steam _;
#endif
#if PLATFORM_X64 && PLATFORM_EPIC
x64epic _;
#endif
#if PLATFORM_PS5
ps5 _; // playstation 5
#endif
#if PLATFORM_XSX
xsx _; // xbox series x and s
#endif
#if PLATFORM_SWITCH
ns2 _; // nintendo switch 2
#endif
public:
void test() { _.test(); }
};
メンバ変数ひとつ宣言するだけなのに、コードがゴチャゴチャして非常に読みづらいです。
どれが使われるのか、ぱっと見て判別できません。
更に悪いことに、ps5 を ps5 と ps5 pro に分ける必要も出ました…なんてことになったら…。
クラスのメンバ変数を対応プラットフォームの数だけ #if を使うのも問題ですが、それぞれのプラットフォームで必要なヘッダファイルが異なるので、#include も同様にゴチャゴチャになります。
この実装方法だと、gege クラスは対応プラットフォームの数だけ依存関係が出来上がります。
通常、ひとつのクラスはプラットフォーム別の処理以外にも、色んなメンバ変数や関数を持つものです。
それらと混ぜてしまうと、gege クラスが何をするクラスで、どのような依存関係があるのか把握するのが難しくなります。
特にバグが出たときに、そのバグ修正が gege クラスを実装した人とは違うとか、実装した本人がクラスの中身を忘れてしまっている場合、クラスの全容を把握するのに時間がかかるので、修正に時間がかかってしまいます。
また、バグを修正できたとしても、見落としている部分が多いと、その修正によって更に別のバグが引き起こされる可能性が高まります。
結局のところ、#if を使う必要はあるのですが、それを書くべきなのは、gege クラスの中ではないです。
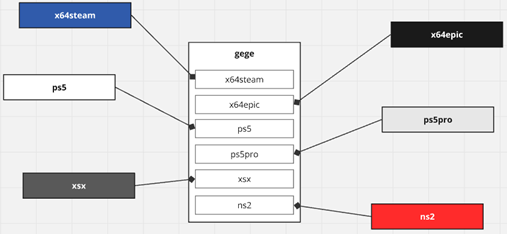
せめて、プラットフォーム別に対応する箇所をひとつにまとめたいですね。
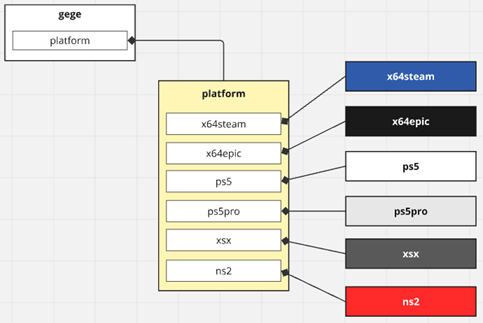
プラットフォーム別の対応を platform に集約します。
この設計だと、gege クラスのコードは以下になります。
class gege {
platform _;
public:
void test() { _.test(); }
};
platform はクラスである必要はありません。
ここでエイリアスを使います。
using platform = #if PLATFORM_X64 && PLATFORM_STEAM x64steam; #endif #if PLATFORM_X64 && PLATFORM_EPIC x64epic; #endif #if PLATFORM_PS5 ps5; // playstation 5 #endif #if PLATFORM_PS5PRO ps5pro; // playstation 5 pro #endif #if PLATFORM_XSX xsx; // xbox series x and s #endif #if PLATFORM_SWITCH ns2; // nintendo switch 2 #endif
#include もこのファイルでやれば良く、gege クラス側のコードを汚しません。
receive_from でクライアントから送られてきたデータを受け取り、recv_buffer (recv は receive の略) 、remote_endpoint、error に値が入ります。
receive_from は同期関数なので、クライアントから接続があるまで、この関数でプログラムの処理が停止します。
運用では、サーバーはクライアントからのデータを受信する以外にも、やるべき処理が沢山あります。
同期関数を使うと、クライアントがデータを送って来るまで、ここでサーバーの処理が止まってしまい、他の全ての処理も行われなくなってしまいます。
同期関数の方が目的と合っているといったケースもあると思いますので、同期関数が不要という話ではありません。
オンラインゲームの運用を想定した場合、同期関数は目的に合いません。
非同期関数 (処理を止めない関数) も用意されているので、運用ではそちらを使います。
非同期関数の使い方は後述します。
クライアントから受け取ったデータは recv_buffer に入り、受け取ったデータサイズは receive_from の戻り値で分かります。
recv_buffer を解析して、受け取ったデータサイズを数えることはできないこともないですが、receive_from の戻り値を使うほうが楽です。
データサイズを数える場合、データが未加工の ASCII 文字列でクライアントから送られてくるという前提なら、以下の関数ひとつで数えることができます。
size_t count = std::strlen(recv_buffer.data());
暗号が複雑だと、暗号化と複合化に時間がかかり、サーバーのパフォーマンスが低下してラグに繋がります。
そういったデータの場合、通常はデータの先頭にデータサイズをセットします。
こういった通信データの加工は運用で必要になりますが、本稿ではこれ以上は掘り下げません。
クライアントの接続があると receive_from 関数を抜けて、次のエラー判定 if (error) … に進みます。
処理は見たまんまです。
エラーがなければ、受信したデータの出力 std::cout … へと進みます。
std::cout << std::string(recv_buffer.data(), length)
気になったのは上記の部分です。
recv_buffer は char 型の配列で、この配列には ASCII 文字が入っています。
std::cout << recv_buffer.data()
と書いても文字を表示してくれそうなのですが、わざわざ std::string に変換しているのは何故でしょうか?
試してみれば分かるかと思い、試してはみたのですが、更に謎が深まりました。
結果から言うと、std::string に変換しなくても char 型配列と同じように文字列で表示してくれます。
「じゃあ、なんで std::string に変換しているの?」
という疑問が沸きます。
例えば、仮の話ですが、文字列は char 型配列の最後の要素が ‘\0’ (ヌル文字) になっている必要があります。
このヌル文字がない場合、std::string に変換すると、勝手に付与してくれるのではないかと思ったのですが、そんな気の利いた機能は持っていませんでした。
これ以上の理由は思いつかないので謎です。
AI が提示したコードなので、深く追求しても得られるものはなさそうです。
サーバー側のサンプルコード解説は、このコードで最後になります。
std::string message = "Server received: " + std::string(recv_buffer.data(), length); socket.send_to(asio::buffer(message), remote_endpoint);
前項の最後のほうで、以下の疑問を投げました。
std::cout << std::string(recv_buffer.data(), length)
上記のコードは std::cout で recv_buffer のデータを出力しています。
recv_buffer は char 型配列なので、std::string に変換しなくても文字列として出力してくれます。
では、何故、わざわざ変換しているのか?
…この答えは、結局分からないままです。
おそらくですが、AI の勘違いではないかと思っています。
以下のコードにも recv_buffer.data() を std::string に変換しているところがあります。
std::string message = “略” + std::string(recv_buffer.data(), length);
しかし、このケースにおいては、この使い方は正しいです。
何故だか分かるでしょうか?
char* s = "文字列" + "文字列"; // C++ でこの演算はできない
文字列リテラルを連結したい場合は並べるだけで良いです。
char* s = "文字列" "文字列"; // 演算子は不要
では、先ほどのコードに戻りますが、
std::string message = “略” + std::string(略);
+ 使ってるやんけ!
と思う人がいるかも知れません。
文字列リテラル同士を + で連結することができないのであり、文字列リテラルと std::string は + で連結できます。
| “文字列リテラル” | + | “文字列リテラル” | 不可 |
| “文字列リテラル” | + | std::string | 可能 |
| std::string | + | “文字列リテラル” | 可能 |
| std::string | + | std::string | 可能 |
では、何故 std::string が絡むと + で連結できるのでしょうか?
⇒ std::string が + で連結できるようにする機能を持っているから?
本当にそうでしょうか?
それが正しいのなら、その機能は std::string のどの部分に定義されているのでしょうか?
これ、標準 C++ のコードを調べて答えにたどり着くのはなかなか面倒だったりします。
std::string なんてクラスは存在しないからです。
もう、いつものパターンになりましたが、std::string はエイリアスです。
std::string の実体は std::basic_string です。
+ で連結する機能をクラスに追加するには、operator+ を使うので、basic_string を定義しているヘッダファイルに operator+ の宣言があるはずです。
ところが、いくら探しても見つかりません。
似たような機能で、operator+= ならありますが、operator+ はありません。
また、C++ の言語仕様なのですが、クラスに定義できる operator+ は、引数をふたつ以上持つことができません。
そのため、クラスの operator+ で “文字列リテラル” + std::string を書けるようにすることはできません。
詳しくは以下のコードに示します。
class hoge {
std::string s_;
public:
hoge(const char* s = "\0") : s_(s) {}
const char* get() const { return s_.c_str(); }
// 文字列リテラルと hoge を + 演算子で連結できるようにしたい。
// hoge h = "文字列リテラル" + hoge("abc");
// ただ、operator+ は引数をふたつ以上持つことができない。
//hoge operator+(const char* lhs, const hoge& rhs); // コンパイルエラー
// 以下は対応可能
// hoge h1;
// hoge h2 = h1 + "abc";
hoge operator+(const char* s);
// 以下は対応できない
// hoge h2 = "abc" + h1;
//hoge operator+(??????);
// hoge が持っている文字列に、文字列を連結する。
// h += "def";
void operator+=(const char* s) { s_ += s; }
}
上記のコードのコメントに記載しましたが、クラスの operator+ を使う場合、以下の組み合わせに対応できます。
| “文字列リテラル” | + | “文字列リテラル” | 不可能 |
| std::string | + | “文字列リテラル” | 可能 |
| “文字列リテラル” | + | std::string | 不可能 |
| std::string | + | std::string | 可能 |
クラスの operator+ は、クラスのインスタンスの右側にある式に対して使われるもので、左側に対しては使えないということです。
hoge + “aaaa”; // インスタンスの右側に対して + を適用する
“aaaa” + hoge; // インスタンスの左側には作用しない。
とは言え、次のコードはインスタンスの左側に作用しています。
std::string message = “略” + std::string(recv_buffer.data(), length);
これはどうやっているんでしょう?
上記の Web ページには std::operator+ と書かれています。
std は名前空間なので、これはクラスの operator+ ではなく、グローバル関数です。
operator+ はクラスに追加することもできますが、クラスでも構造体でもない、ただの関数としても定義できるということです。
クラスの operator+ は引数をふたつ以上持つことができませんが、関数の operator+ なら可能です。
前述のコードの続きです。
// これなら hoge h2 = "abc" + h1; に対応できる。
hoge operator+(const char* lhs, const hoge& rhs) {
return hoge(std::operator+(lhs, rhs.get()));
}
全ての謎が解けました。
最後になりましたが、以下の部分については、ここまでの解説を読んでいれば分かると思います。
socket.send_to(asio::buffer(message), remote_endpoint);
send_to 関数は初めて出てきましたが、名前の通り「~に送る」という意味ですので、message を remote_endpoint に送信しています。
これも receive_from 関数と同様に同期関数 (ブロック関数) ですので、関数の処理が終わるまで、ここで停止します。
receive_from は、いつ来るか分からないクライアントのデータを永久に待つため、非同期で処理しないと永久に処理が止まってしまいます。
対して send_to は、データを送ってしまえばそれで終わりですから、非同期処理するべきかどうかは今のところ分かりません。
UDP は TCP と違って、データが届かなくても気にしない通信方法です。
データが届かなくても、届いたときに壊れていても、送り直すということはしません (TCP は確実に届けてくれます)。
そのため、TCP と違って、処理はすぐに終わるだろう…という予想はできます。
予想はできますが、それが正しいとは限りません。
データの送り先が大量にある、送るデータが巨大、1 秒間に 1000 回データを送る…といった状況で、send_to がどのように振る舞うのかを検証する必要があります。
検証した結果、特定の条件では send_to が結果を返すのに時間がかかる…と判明した場合に、非同期の send_to に切り替えるのが良いと思います。
非同期処理は扱いが難しいので、同期関数で済むなら同期関数を使ったほうが良いです。
クライアント側のコードはサーバー側のコードと半分くらいは同じなので、サーバー側と違う部分だけ読み解きます。
具体的には以下の部分になります。
asio::ip::udp::socket socket(io_context, asio::ip::udp::endpoint(asio::ip::udp::v4(), 0)); asio::ip::udp::resolver resolver(io_context); asio::ip::udp::endpoint remote_endpoint = *resolver.resolve(asio::ip::udp::v4(), "127.0.0.1", "8080").begin();
このサンプルコードなのですが、処理を書く順番が適切ではありません。
プログラムの挙動は変わらないんですが、socket を書くのが早すぎます。
正しくは、以下のコードになります。
asio::ip::udp::resolver resolver(io_context); asio::ip::udp::endpoint remote_endpoint = *resolver.resolve(asio::ip::udp::v4(), "127.0.0.1", "8080").begin(); // socket の宣言を socket が必要になるまで遅らせた asio::ip::udp::socket socket(io_context, asio::ip::udp::endpoint(asio::ip::udp::v4(), 0));
C 言語はブロックの最初に変数を全て宣言する必要がありますが、C++ では基本的に必要になったタイミングで宣言するものです。
※この世には白黒つけられることが、そもそもあまりなく、そうするには多くの前提条件を設定する必要があります…。
そうするべき理由は、今使用している変数を短期記憶から減らすためです。
自分が覚えられるかどうかを基準にするのではありません。
一般的に覚えられない人が多い、あるいは、他にも沢山のことを同時に覚えておく状況が多いため、新しく覚えるものを可能な限り減らしたほうが効率よく問題の解決に集中することができます。
コードを書く基準は常に自分ではなく、広く認知されている理論やデータを基準にします。
学習を始めたばかりの頃は、その基準となる知識がないので、いくつか私のお薦めを紹介します。

こちらはコードを書くときに気を付ける点を分かりやすくまとめたバイブルのようなもので、私は内容が全て頭に入るまで何度も繰り返し読みました。
素晴らしい書籍です。 より具体的に学習するのに最適です。
結論が出るまでにどのような議論があったのかも記載されています。
Unreal Engine コーディング規約
より広く学習するのに最適です。
標準 C++ だけでなく、特定の分野における独自のルールを学習できます。
ゲーム開発に興味があるなら、今のところは必修です。
void SomeFunc() {
int a = 0;
int b = 1;
// ブロック A
{
a += 2;
// a はもう使わない
}
// ブロック B
{
b += 3;
// b はもう使わない
}
}
変数 a はブロック A の中だけで使い、変数 b はブロック B の中だけで使います。
ところが、a も b もブロック A と B の外で宣言しています。
そうすると、SomeFunc を抜けるまで、a と b が残ります。
変数 a はブロック A の中でしか使わないのに、ブロック A の外でも変数 a のことを覚えておいて、値が参照されていないか、値が変わらないかを気にする必要が出てしまいます。
変数 b も同じように、SomeFunc 関数の最初から最後まで変数 b のことを気にしなければならなくなります。
上記のコードは可能な限りシンプルにしたものなので問題にはならないですが、実際の運用では複雑で巨大なコードの中に、この問題がしれっと潜んでいます。
void SomeFunc() {
int* p = new int(0);
// ブロック A
{
delete p;
}
// ブロック B
{
int a = *p; // エラー(運が良ければコンパイラが見つけてくれるかも?)
}
}
上記は実際にクラッシュを引き起こす、超シンプルなサンプルコードです。
例えば、コードを書き始めたときは、ポインタ変数 p は、ブロック A の中だけで使うつもりだったけれども、その後、コードの追加や修正を繰り返すことで、そのことを忘れてしまった。
ブロック B を追加したとき、ブロック A のことをすっかり忘れていて、ブロック A で delete した p の値を参照し、不幸なことにコンパイルも通ってしまった。
プログラムを実行したときにブロック B でクラッシュし、あれこれ調べて、ブロック A で delete していたことに気づく…。
こういうことは普通に起きます。
最初からブロック A の中で変数 p を宣言していれば、こんなことは起きませんでした。
それによって、使わなくて良いはずの貴重な時間を使ってしまう…ということになります。
void SomeFunc() {
// ブロック A
if (int* p = new int(0))
{
delete p;
}
// ブロック B
{
int a = *p; // エラー(これは確実にコンパイラが検出してくれる)
}
}
asio::ip::udp::resolver resolver(io_context); asio::ip::udp::endpoint remote_endpoint = *resolver.resolve(asio::ip::udp::v4(), "127.0.0.1", "8080").begin(); asio::ip::udp::socket socket(io_context, asio::ip::udp::endpoint(asio::ip::udp::v4(), 0));
並び替え後のコードを見て行きます。
asio::ip::udp::resolver resolver(io_context);
クライアント側のサンプルコードでは、resolver (リゾルバー) と呼ばれるものを使用しています。
サーバー側のサンプルコードには出てきませんでした。
resolve は解決するという意味なので、解決するもの (人、機能) という意味になると思いますが、何を解決するのでしょうか?
答えが決まっているものは AI に聞くのが手っ取り早いです。
ホスト名は分かるけど、それに対応する IP アドレスとポート番号が分からない問題を解決する…ということになると思います。
例えば、当ブログの URL は https://dokuro.moe ですが、実際そんなサーバーは存在しません。
ブラウザにブログを表示するためのデータは、どこかのサーバーにあります (どこのサーバーにあるかはセキュリティに関わるので公開しません)。
このサーバーにアクセスするには、IP アドレスとポート番号が必要です。
この URL でサーバーにアクセスできているのは、名前解決と呼ばれる面倒な処理を、ブラウザとサーバーがやってくれているからです。
これ以上はサーバー構築の話になるので掘り下げません。
興味がある方は、ネームサーバー (DNS サーバー) について AI に聞いてみてください。
サンプルコードに戻ります。
resolver はクライアントからサーバーにアクセスするための名前解決をしてくれるクラス (正確にはエイリアス) ということが分かりました。
asio::ip::udp::resolver resolver(io_context) は、ただインスタンスを宣言しただけですので、このクラスの使い方を確認するため、次の行に進みます。
asio::ip::udp::endpoint remote_endpoint = *resolver.resolve(asio::ip::udp::v4(), "127.0.0.1", "8080").begin();
情報を詰め込みすぎですので、ひとつずつ分解します。
const asio::ip::udp udp { asio::ip::udp::v4() };
const std::string host{ "127.0.0.1" };
const std::string port{ "8080" };
using results_t = asio::ip::udp::resolver::results_type;
const results_t results{ resolver.resolve(udp, host, port) };
// host:port が見つからない場合、例外がスローされる
asio::ip::udp::endpoint remote_endpoint{ *results.begin() };
上から 3 行は説明する必要はないと思います。
using results_t = asio::ip::udp::resolver::results_type;
ここまでに何度も出て来たエイリアスの定義ですが、一点、以下の部分が気になります。
results (result の複数形)
この変数で受け取る値は、ひとつではなく、複数の場合がある…ということになります。
なんの値を受け取るのか?は、次の行で分かります。
const results_t results{ resolver.resolve(udp, host, port) };
これは results 変数の宣言時に初期値をセットしています。
以下と同じです。
const results_t results = resolver.resolve(udp, host, port);
resolver.resolve(udp, host, port)
複数の値を返す可能性があるのは、こちらの関数呼び出しです。
using results_t = asio::ip::udp::resolver::results_type;
戻り値の型は、asio::ip::udp::resolver::results_type ですが、これもエイリアスです。
typedef basic_resolver_results<InternetProtocol> results_type;
実際の型は basic_resolver_results<T> クラスだと分かります。
InternetProtocol はテンプレート引数で、UDP を使う場合は basic_resolver_results<asio::ip::udp> になります。
// クラスのテンプレート引数
template <テンプレート引数> class hoge {};
// 関数のテンプレート引数
template <テンプレート引数> void hoge() {}
asio::ip::udp はサーバー側のサンプルコードにも出てきましたが、クラスです。
basic_resolver_results<InternetProtocol> は、udp クラスを扱うことができる basic_resolver_results クラスということになります。
results は複数形なので、複数の値を返すことを示唆しています。
C++ で複数の値を扱う方法と言えば、std::vector か、ただの配列なのかな?と予想できるのですが、クラスはひとつです。
results のインスタンスはひとつですが、内部に複数の値を持つことができます。
ひとつのクラスの中に複数の値を持っているなら、各々の要素にはどうやってアクセスするのでしょうか?
std::vector みたいに [] を使ったり、iterator を使うのでしょうか?
公式ドキュメントに記載されている通りですが、[] を使ってアクセスすることはできません。
iterator のみです。
要するに、要素へのランダムアクセスはできません。
iterator を使って、先頭から順番にたどる必要があります。
と言っても、要素数はせいぜい多くても数十個くらいで、ほとんどは数個、あるいは 1 個か 2 個程度でしょうから、目的の要素にたどり着く命令数が O(n) でも問題ないと思います。
n 番目の要素を取得する方法は以下になります。
constexpr int ACCESS_NUMBER{ 2 };
if (ACCESS_NUMBER > 0 && results.size() >= ACCESS_NUMBER) {
auto element{ std::next(results.begin(), ACCESS_NUMBER - 1) };
std::cout << "[" << (ACCESS_NUMBER - 1) << "]="
<< element->host_name() << ":" << element->service_name()
<< std::endl;
}
resolver を使う際に注意する点がもうひとつあります。
名前解決には時間がかかることがある。
同じ PC 内でソケット通信をする場合は、ネームサーバーにアクセスする必要がないですし、気にならないくらい速く通信することができます。
実際の運用では、ネームサーバーと通信することを想定する必要があります。
resolve 関数は同期関数なので、名前解決が終わるまでそこで処理が停止するブロック関数です。
処理をブロックしない非同期関数も用意されています。
AI に聞けば使い方は分かると思いますが、運用しているコードに組み込むには大抵の場合、手直しが必要になります。
運用しているコードを AI に教えて、修正案を提示してもらうこともできます。
ただし、AI が提示したコードの良し悪しを判断するには、AI 以外から習得した知見が必要です。
近いうちにそれも必要なくなると思いますが、まだ最終的な判断は人が行う必要があります。
asio::ip::udp::endpoint remote_endpoint{ *results.begin() };
次の行で results の最初の要素にアクセスして、remove_endpoint にコピーしています。
手直ししたサンプルコードに記載しましたが、results の要素がひとつもない (カラの) 場合、ここへ来る前に例外がスローされます。
const results_t results{ resolver.resolve(udp, host, port) };
// host:port が見つからない場合、例外がスローされる
asio::ip::udp::endpoint remote_endpoint{ *results.begin() };
*results.begin()
これは良くある書き方ですが、以下のふたつのことを同時におこなっています。
auto i{ results.begin() };
iterator の最初の要素にアクセス。
ここで取得した値 i は iterator なので、そのままでは endpoint を取得できません。
auto value{ *i };
最初の要素を取得。
iterator に対応する値を取得するには、* を使います。
運用を考えるなら、これでは足りません。
以下の点を考慮する必要があります。
asio::ip::udp::endpoint remote_endpoint{ *results.begin() };
この変数 remote_endpoint は値を書き換える必要があるのか、値を参照するだけなのか?
値を書き換える必要がある = ReadWrite.
値を参照するだけ = ReadOnly.
どっちでも良い場合は、remote_endpoint のスコープを狭くすることで、コードの安全性が向上します。
remote_endpoint のスコープ (使える範囲) はどれくらいでしょうか?
asio::io_context io_context; asio::ip::udp::resolver resolver(io_context); asio::ip::udp::endpoint remote_endpoint = *resolver.resolve(asio::ip::udp::v4(), "127.0.0.1", "8080").begin(); asio::ip::udp::socket socket(io_context, asio::ip::udp::endpoint(asio::ip::udp::v4(), 0)); std::string message = "Hello from client!"; socket.send_to(asio::buffer(message), remote_endpoint); std::array<char, 1024> recv_buffer; asio::error_code error; size_t length = socket.receive_from(asio::buffer(recv_buffer), remote_endpoint, 0, error);
remote_endpoint は最後まで残しておく必要があるので、スコープは広いです。
スコープが広くなるほど、どこで値が変わるのかを把握するのが難しくなります。
把握するのが難しいということは、バグが出る可能性が上がり、バグが出た場合に修正するコストも上がる…ということになります。
そのため、remote_endpoint は const にすることが望ましいです。
ところが、remote_endpoint を const にすることはできません。
何故だか分かるでしょうか?
template<typename MutableBufferSequence>
std::size_t receive_from(
const MutableBufferSequence & buffers,
endpoint_type & sender_endpoint,
socket_base::message_flags flags,
asio::error_code & ec);
公式のドキュメントを見ると、socket.receive_from に渡す endpoint_type (= remote_endpoint = asio::ip::udp::endpoint) には const が付いていません。
remote_endpoint に const を付けると、receive_from に渡すときに「const 外し」をする必要が出ます。
この「const 外し」は動作未保障なので、基本的に C++ でやってはいけないこと です。
動作未保障というのは、「昨日確認したときは問題なかったけど、今日確認したらクラッシュした。」…という可能性があるものです。
この「いつどうなるか分からない…。」という不安を抱えないようにコードを組む必要があります。
問題ないことを確認できれば良いです。
そのためには、コンパイルする度に色々と条件を変えて動作確認したり、アセンブラのコードを確認して変換する処理自体に問題がないことを確認する必要が出てくるので、余計にコストが高くなります。
const 外しは問題がある処理ですが、const を付けることは問題ありません。
ある時は const を付けて、ある時は const を付けずに使う…ということは普通にあります。
スコープの広い変数を扱うときに問題になるのは、「どこで値を変更しているのかを把握するのに時間がかかる。」という点ですので、この問題を解決してしまえば良いということになります。
asio::ip::udp::socket socket(io_context, asio::ip::udp::endpoint(asio::ip::udp::v4(), 0));
こちらで最後になります。
クライアント側のソケットを生成するのに、io_context と endpoint を指定しています。
いつも通り、1 行に情報を詰め込みすぎですので、ひとつずつ分解したコードを以下に示します。
auto GetClientEndpoint = []() -> asio::ip::udp::endpoint {
const asio::ip::udp udp {asio::ip::udp::v4()};
constexpr uint16_t PORT_NUMBER{0};
asio::ip::udp::endpoint endpoint {udp, PORT_NUMBER};
return endpoint;
};
asio::ip::udp::socket socket{io_context, GetClientEndpoint()};
endpoint の生成処理をラムダ式にして、戻り値を受け取るだけで済むようにしています。
ラムダ式を使わずに、.cpp ローカルな関数でも良いです。
カプセル化した理由は以下です。
1. 局所変数の udp や port のスコープを狭くするため。
2. 関連する処理をひとまとめにするため。
3. 一連の処理に名前を付けて、その処理が何をするためのものなのか?を明確にするため。
この処理で気になるのは、ポート番号 (PORT_NUMBER) に 0 を指定しているところです。
この 0 という値は、コードを書く上でいくつかの意味を持っています。
1. 整数値の 0 として使う。
⇒ この値を使うことを明確に意図している。
2. 何の値でも構わないが省略できないので、とりあえず指定している。
⇒ 都合が悪かったら変更するつもり。
3. 初期値として指定している。
⇒ 未指定だと何の値になるか分からないので初期化した。
この 0 が、どのような目的で指定している値なのかが、コードを見ただけでは分かりません。
目的を理解するには、asio のコードを読む必要があります。
ただ、asio のコードは高度に抽象化されているため複雑で分かりにくく、解読するのに様々な知見が要求されるので、初心者向けではありません。
そのため、詳しい説明はしませんが、asio のコードをたどっていくと、PORT_NUMBER 0 はそのままコア部分のソケット通信 API の関数に引き渡されています。
従って、ここでの意味は、1. です。
おそらく、このポート番号は何でも構いません。
サーバーと通信を行うときに、クライアント側で使うポート番号になります。
ポート番号はデータの届け先としても使いますが、クライアントからサーバーに向かって「出ていく」ときの出口としても使います。
このポート番号はサーバー側に伝達されるので、サーバーがクライアントにデータを送り返すときの宛先として使われることになります。
これより前の項では「ソケット通信」のサンプルコードについて深く読み解いてきましたが、そもそも「ソケット通信」ってなに?という方のために軽く説明すると、ふたつ以上のプログラム同士で通信することです。
ソケット通信のプログラムはめんどくさいだけで難しくはないのですが、問題はそれぞれのプログラムがどこにあるか?によって、プログラム以外のネットワーク構築の知識が必要になります。
プログラムを配置する場所としては、以下のようなケースが考えられます。
1. 同じマシンの中にある。
2. 同じマシンだが、別々の OS の中にある。
3. LAN ケーブルで繋いだふたつ以上のマシンの中にある。
4. Wifi で繋がっているふたつ以上のマシンの中にある。
5. インターネットで繋がっているふたつ以上のマシンの中にある。
マシンはそのまま機械のことを指しますが、PC だったり、ゲーム機だったり、ネットワーク機能を持ったなんらかの機器だったりと、幅広い対象を指しています。
数字が大きいほど難易度が高くなります。
ブルートゥースで通信する方法は分からないです。
2. は、どちらも同じ PC で動かしているのですが、片方は Windows で動かしていて、もう片方は Windows のサブシステムや、OS のエミュレーターなどを使って別の OS で動かしている…というケースが考えられます。
困ったことに、難易度が高くなるのはプログラムのコード以外の部分で、ファイアーウォール、セキュリティソフト、ルータの設定(ポート解放)などを地道に調査&トライ&エラーを繰り返して設定していく必要があります。
使用しているアプリや機器によって設定方法が変わるため、とても厄介です。
ここでは深い説明は行いません。
調べる取っ掛かりになる程度の情報を共有します。
以下の流れで学習を進めて行けば、ネットワークプログラミングつよつよエンジニアになれるかも知れません。
1. ここで提示した情報を AI に聞いてサンプルコードを提示してもらう。
2. そのサンプルコードをコンパイルして動作確認する。
3. 動作確認ができたら、改善点を検討する。
AI はたぶん、どれを使っても大して差はないと思います。
私は Google Gemini の無料版を使っています。

ちなみに、こちらの画像は Google Gemini を擬人化するとしたら、どんなキャラクターになる?という話題で、キャッキャウフフしながら議論していたら、Gemini が生成してくれたものです。
画像生成はリクエストしておらず、Gemini が自発的に生成してくれました。
Gemini (ふたご座) だから双子キャラで、目の輝きは Gemini のアイコンを表現しています。
「アニメ調の方が良くね?」と提案しましたが、リクエスト過多でキャンセルされてしまいました。
これ以上はお布施しないとダメそうです。
本稿で説明していることを実際に試してみます。
エンジニアは業務の中で、様々なプログラム、ツール、アセット、プラグイン、API などのインストールや検証を行います。
実際に試してみることはとても重要です。
上手くいかなければ、何故うまく行かないのか?を深く追求することになり、その知見があとあと役に立ちます。
動作したら、そこで終わりではありません。
もっとより良い方法はないのか?
現在の業務に反映するにはどうすれば良いか?
汎用的な API にするには、どこをどのように改造すれば良いのか?
などを検討して、実際に試してみると良いです。
こういった経験を通じて、ソフトウェア設計の知見の必要性が分かるようになるかも知れません。
というより、やればやった分だけできるようになります。やらなければゼロです。
1. 同期関数を使っている。
2. 接続先とコネクションを持てない。
3. パケットロスへの対応がない。
4. パケット順が保証されていない。
5. パケットを圧縮していない。
6. パケットを暗号化していない。
7. パケットをシリアライズ・デシリアライズする仕組みがない。
これはサンプルコードの説明で何度か出てきましたが、同期関数を使うと、そこで処理が止まってしまいます。
ゲームなど、通信以外の処理も常に行う必要がある場合は、非同期関数に置き換える必要があります。
これは AI に聞けばサンプルコードを提示してくれることを確認しているので、置き換え自体は簡単です。
サンプルコードは UDP というプロトコルで通信しています。
UDP と対極的なプロトコルに TCP があります。
UDP は軽いのですが、通信相手とコネクションを張るという TCP が持っている機能を UDP は持っていません。
TCP ほど厳密ではなくても良いので、UDP にも似たような仕組みが必要になります。
それは自分で作る必要があります(AI に頼めばコードを提示してくれるかも知れません)。
そんなに凝った仕組みは必要ないです。
TCP と同じことをするなら、TCP を使うべきです。
UDP を使う理由は、TCP より信頼性が落ちたとしても速く通信するためです。
例えば、サーバー (ホスト) なら、データを送って来たクライアントのエンドポイントが分かるので、それを保持する仕組みが必要です。
クライアントは複数必要になることが多いです。
クライアントなら、接続先の IP アドレスとポート番号をコードに持たせたり、ロビーで待ち合わせしたホストのエンドポイントを保持したり、接続先の IP アドレスとポート番号を入力するプロンプトや UI を追加したり…といった方法で、接続先のエンドポイントを取得して、それを保持する仕組みが必要です。
昔のオンラインゲームでは UDP を使っていることがあります。
例えば、「リネージュ」や「ストーンエイジ (サービス終了しています) 」は UDP を使っていると開発者から聞きました。
UDP はデータを送信したら、それで終わりです。
データが届いたか?届いたデータが壊れていないか?といったことは気にしません。
データが届かなかったことをパケットロスと言います。
ローカルホストでの通信では見たことはありませんが、インターネット越しに通信を行うとパケットロスが起きます。
パケットロスを検出する仕組みは、なかなか厄介です。
A. データが正しいことを検証する仕組みが必要。
B. データが届いたことを検出する仕組みが必要。
A. についてですが、CRC やチェックサムと呼ばれるもので、送るデータをいろいろ加工して、そのデータ固有の数値に変換します。
この数値をデータに含めます。
データが届いたら、届いたデータを同じアルゴリズムを使って、そのデータ固有の数値に変換します。
両方の数値が同じなら、データが正しいと分かります。
データが正しくない場合、再度、同じデータを送るよう通信先に要求を出します。
B. についてですが、データそのものが届かなかったら、また送るように要求を出す仕組みです。
そもそも、データが届いてないことをどうやって検出するのか?というのが難しいです。
これは TCP の仕組みを参考にして作ることになりますが、AI に聞けばサンプルコードを提示してくれます。
以下の質問を投げるだけです。
「udp で簡単なパケットロス対策をするコードを教えてください。C++20とasioを使ってください。 」
これも、TCP を使えば気にする必要はありません。
UDP は連続してパケット (データ) を送ると、送った順に届かないことがあります。
そのため、データを送る順番を送信先に伝える仕組みが必要です。
データを受け取る側は、データが順番通りになるよう、届いたデータを並び替える必要があります。
データサイズは可能な限り小さくすることで、ラグの軽減に繋がります。
これは回線の帯域の問題ですが、帯域には限りがあります。
圧縮したデータは解凍する必要があるので、送る側はデータを圧縮し、受け取る側は圧縮されたデータを解凍できる必要があります。
LZH のような重いアルゴリズムは使えません。圧縮と解凍に時間がかかるとゲームが遅くなるからです。
軽くて圧縮率の高いアルゴリズムを使います。
オンラインゲームに適した圧縮アルゴリズムを AI に聞けば良いと思います。
データを暗号化するのは、チート対策です。
リリース版では必要ですが、開発版では暗号化は必須ではありません。
パケットの圧縮と同じように、暗号化と複合化に時間がかかるとゲームが遅くなります。
軽いアルゴリズムを使う必要がありますが、暗号化に使う鍵の扱い方をよく理解して、管理を徹底しないと簡単に解かれてしまいます。
とあるオンラインゲームでは、メンテ時に暗号パターンを変更したのに、メンテが開けてから30分で解除されたことがあるそうです。
有名なオンラインゲームのチートは金儲けに直結しているので、チーターのレベルも素人ではありません。
オンラインゲーム向けの暗号化ライブラリも AI に聞けば、いくつか候補を上げてくれます。
struct PlayerStateSC {
uint16_t hp{0};
uint16_t mp{0};
uint16_t condition{0};
};
例えば、サーバーからクライアントに上記のデータを送信したい場合、この構造体の値をシリアライズする必要があります。
PlayerStateSC data_to_send{100,10,0};
// 一番簡単なシリアライズ
std::vector<char> send_buffer{sizeof(data_to_send)};
std::memcpy(send_buffer.data(), &data_to_send, sizeof(data_to_send));
//
このシンプルなシリアライズ処理は、単純な型であれば機能するのですが、メンバにポインタを持っていたり、std::vector を持っていたりすると、正しくシリアライズできません。
シリアライズについても AI に聞けばサンプルコード付きで答えを提示してくれます。
プログラミングの学習でグーグル検索する時代は終わりましたね。
AI に聞くだけで済むようになりました。
我々は既に転スラの大賢者を手にしています。
今のところ、人間は司令塔かつ下請け (AI) が作ったコードを使って、アプリを組み立てる工場の作業員です。
ただ、どんなコードが必要なのか?どのコードをどの順番で組み合わせるのか?について、AI から聞き出す能力が必要です。
それから、AI が提示した部品に問題がないかを確認するのは、今のところ人間がやる必要があります (時間の問題だと思います)。
どういった質問をすれば、自分が知りたい答えにたどり着けるのか?を考える能力を鍛える必要がありますが、その方法は私には分かりません。
私がゲームプログラミングを始めたのは、16 ビットの時代からです。
当時、「100 メガショック!なんとかかんとか…」というゲーム機の広告があったんですが、本当にショックでした。
私が作っていたレベルのゲームは、フロッピーディスク 1 枚 (1 メガちょっと) に 100 個以上は余裕で入ったので、「100 メガも使えたらなんでもできるじゃん!」とか思ってました。
誰にも公開していないしょうもないゲームはたくさん作りましたし、2D ならゲームエンジンを使わずに作ることができます。
ゲーム開発に必要な GUI アプリを作ることもできますし、CI の環境構築から、オンラインゲーム用のサーバーを Linux ディストリビューションをインストールして、環境設定して、必要なアプリをインストールして構築することもできます。
歳をとっている分、色んな知見があるので、何を質問すれば答えにたどりつけるのかは分かります。
けれども、私がこれまでに得た知見の何がそうさせているのか?は分かりません。
近い将来、ゲームはほぼ AI が勝手に作るようになると思います。
人間が「こんなゲームやりたい。」と言うと、AI が数秒で作ってくれます。
人間が指示しなくても、トレンドからニッチなものまで、AI が勝手に考えて作ります。
対戦ゲームの最高のパートナーは AI になりますし、協力プレイの一番しっくりくる仲間も AI になります。
淋しかったら会話もしてくれます。
今の私たちは、そこまでの過渡期を経験しているだけです。
時間の問題です。
私たちが生き残るには、どうすればいいのでしょうね?
私はもう少し AI が成長したら、宇宙を創造しようと思ってます。
もちろんバーチャルですが、あらゆることが自動化できないと無理です。
私はきっかけと理 (ことわり) を創るだけで、あとはずっと観察ですね。


本稿で使用している画像は Bing Image Creator または Google Gemini で生成したものです。